I’ll do another round and some summary.
@marklynch
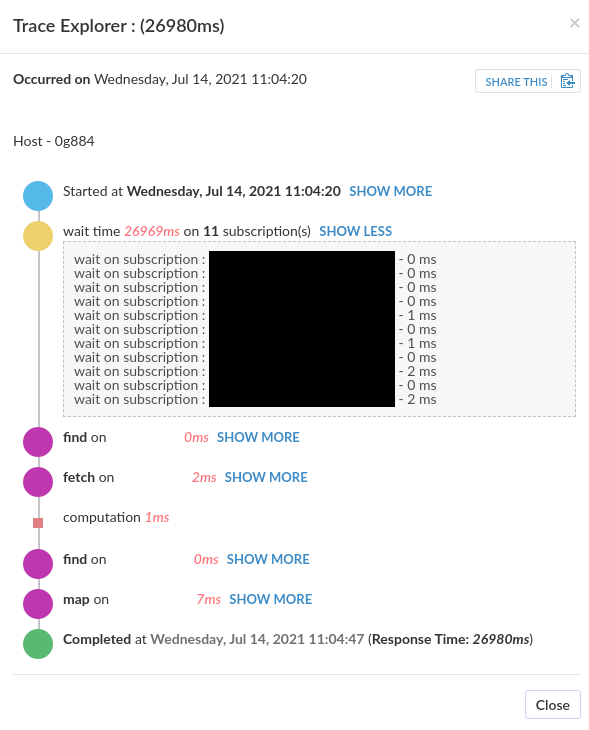
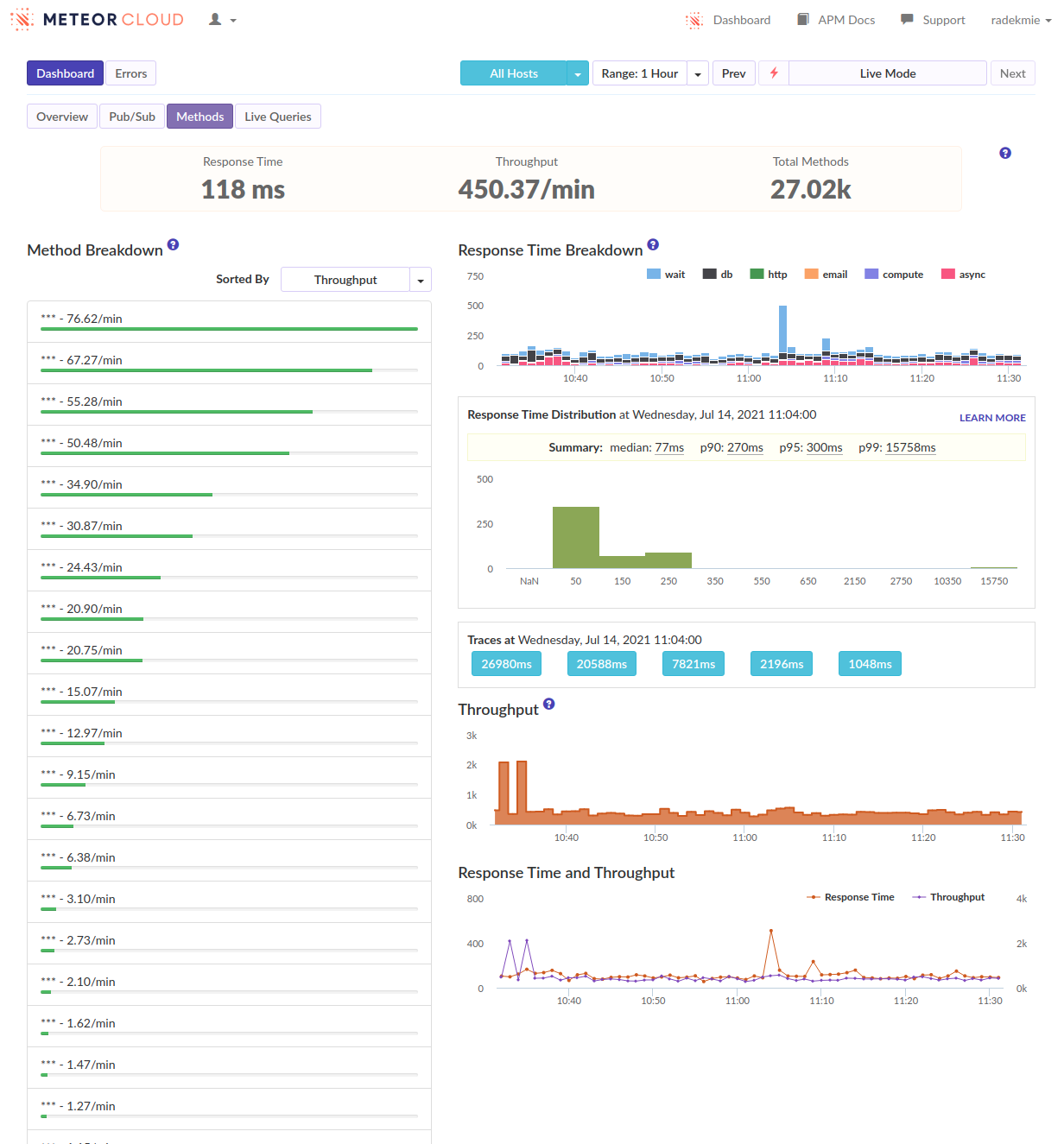
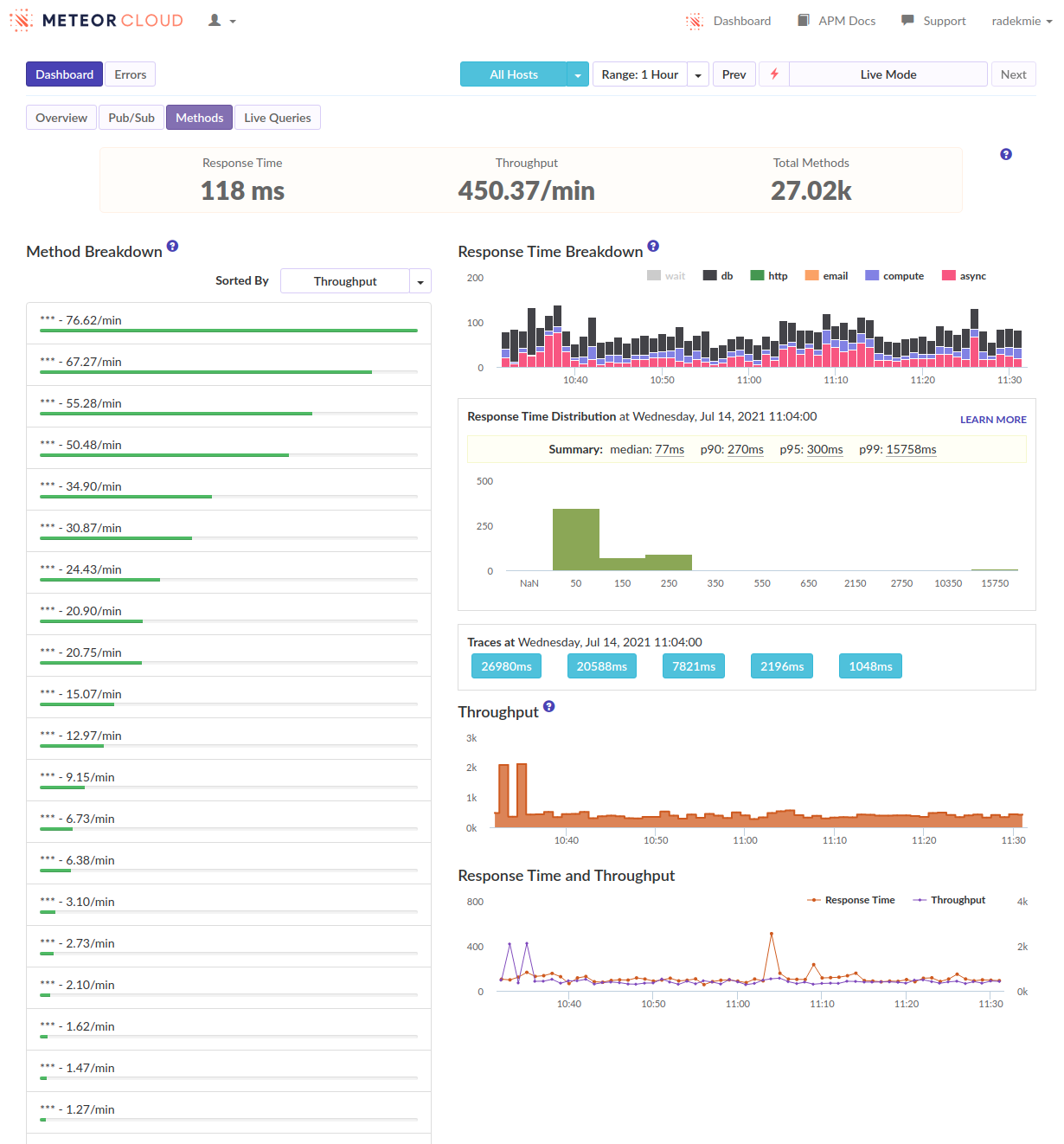
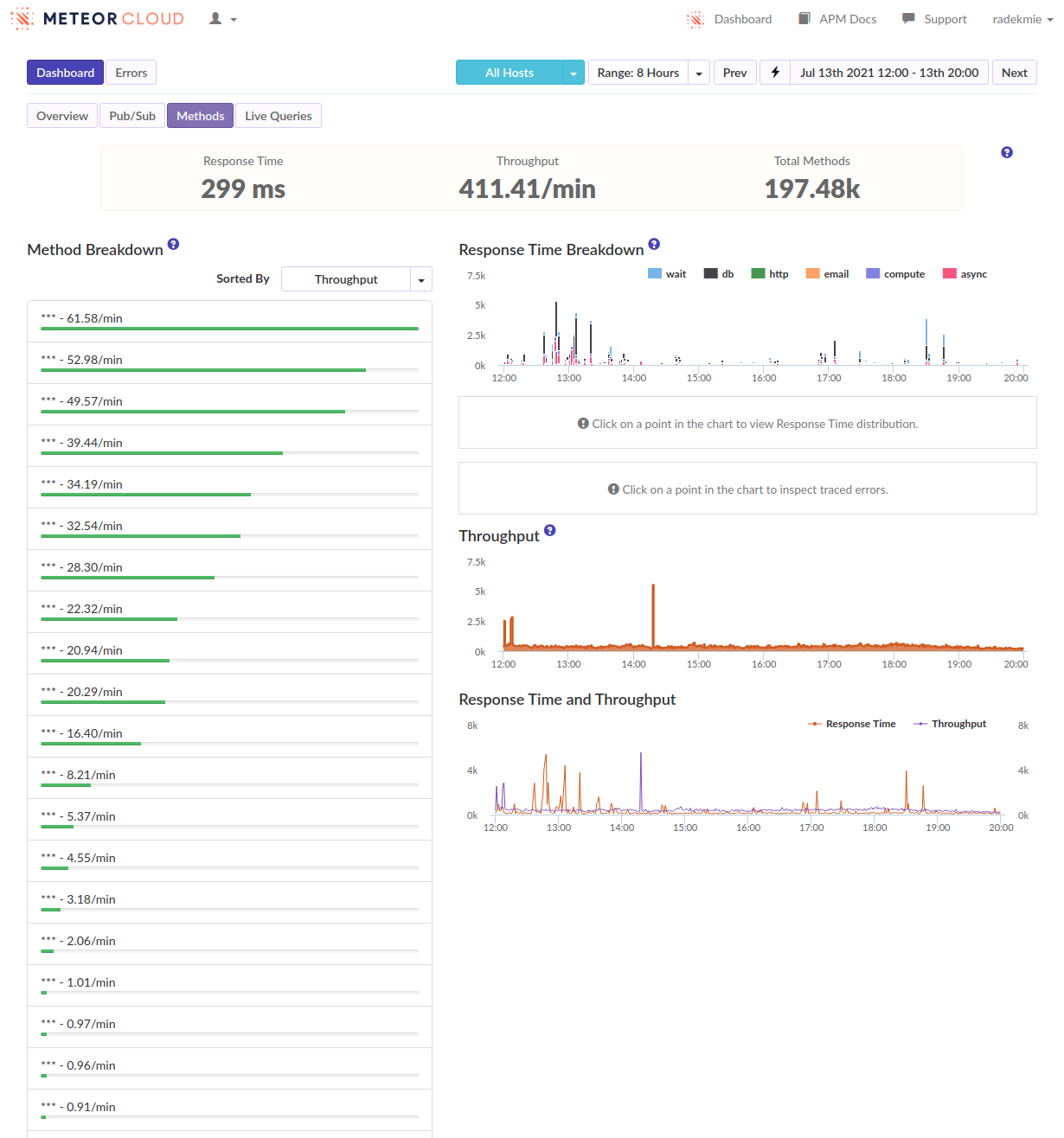
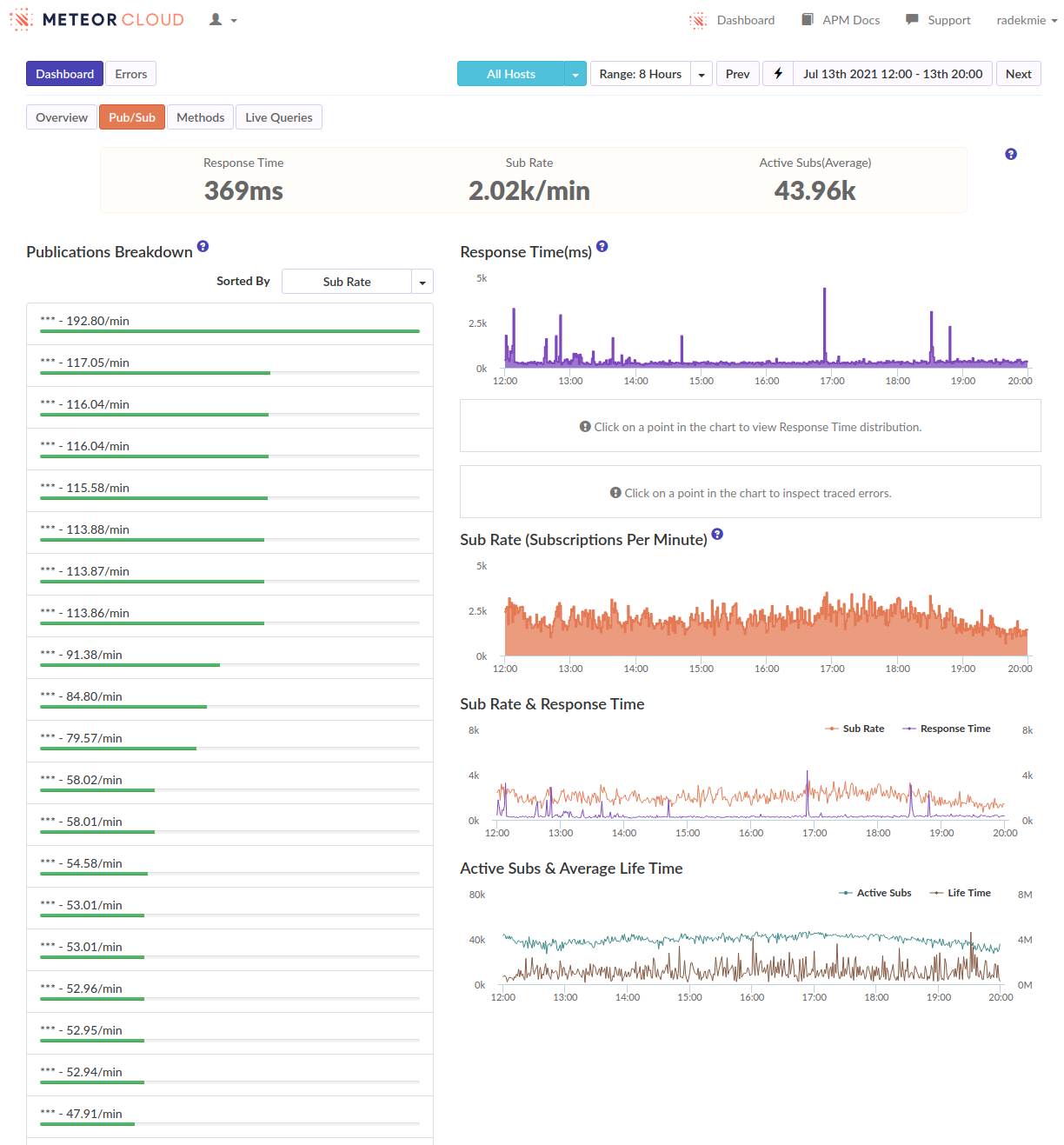
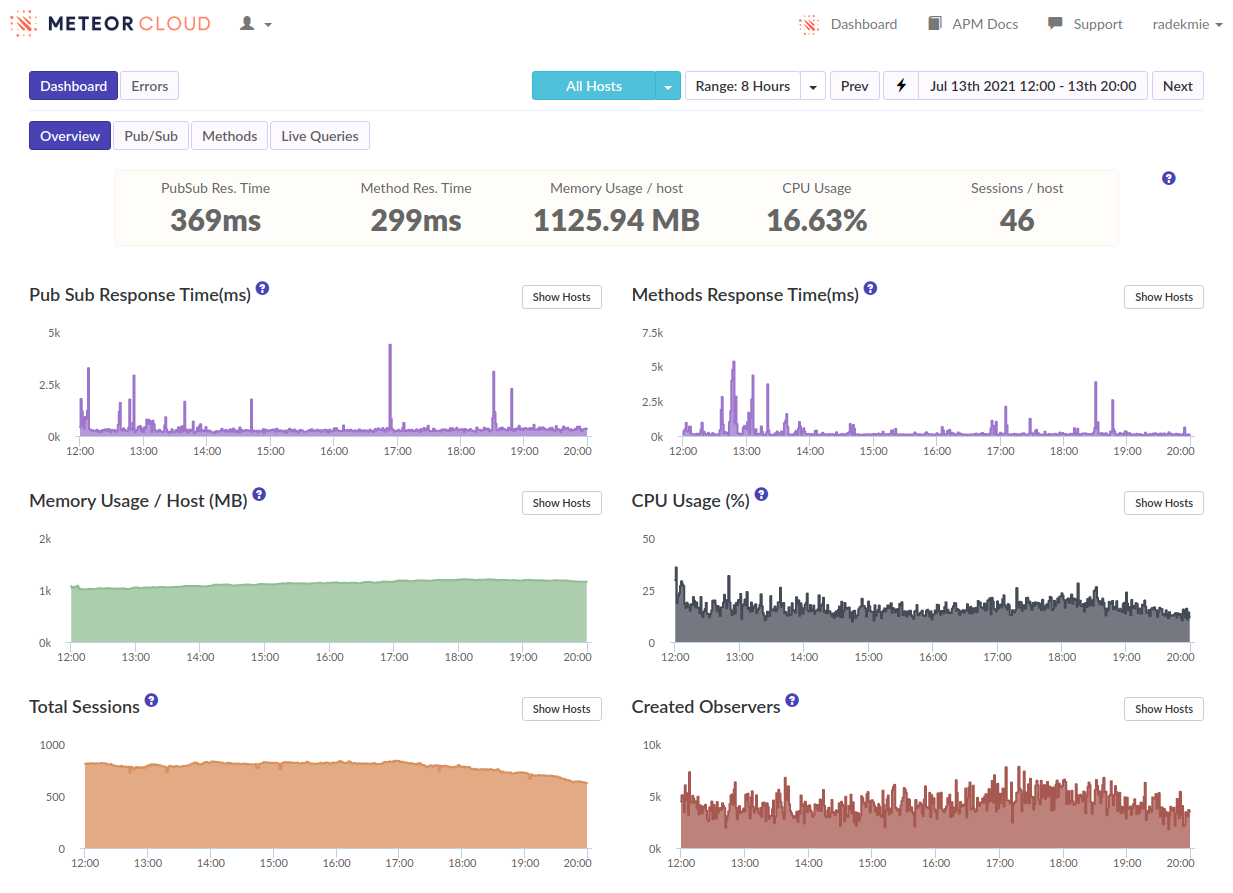
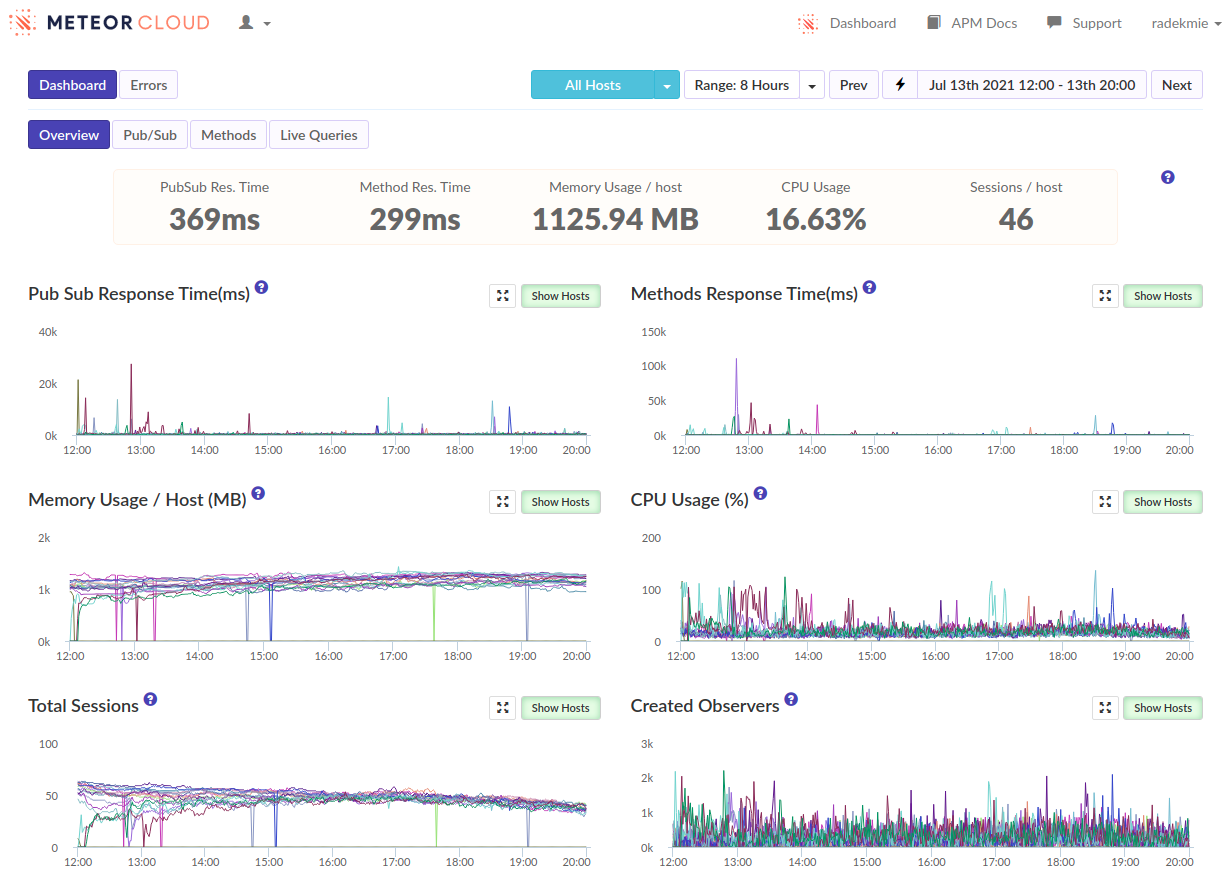
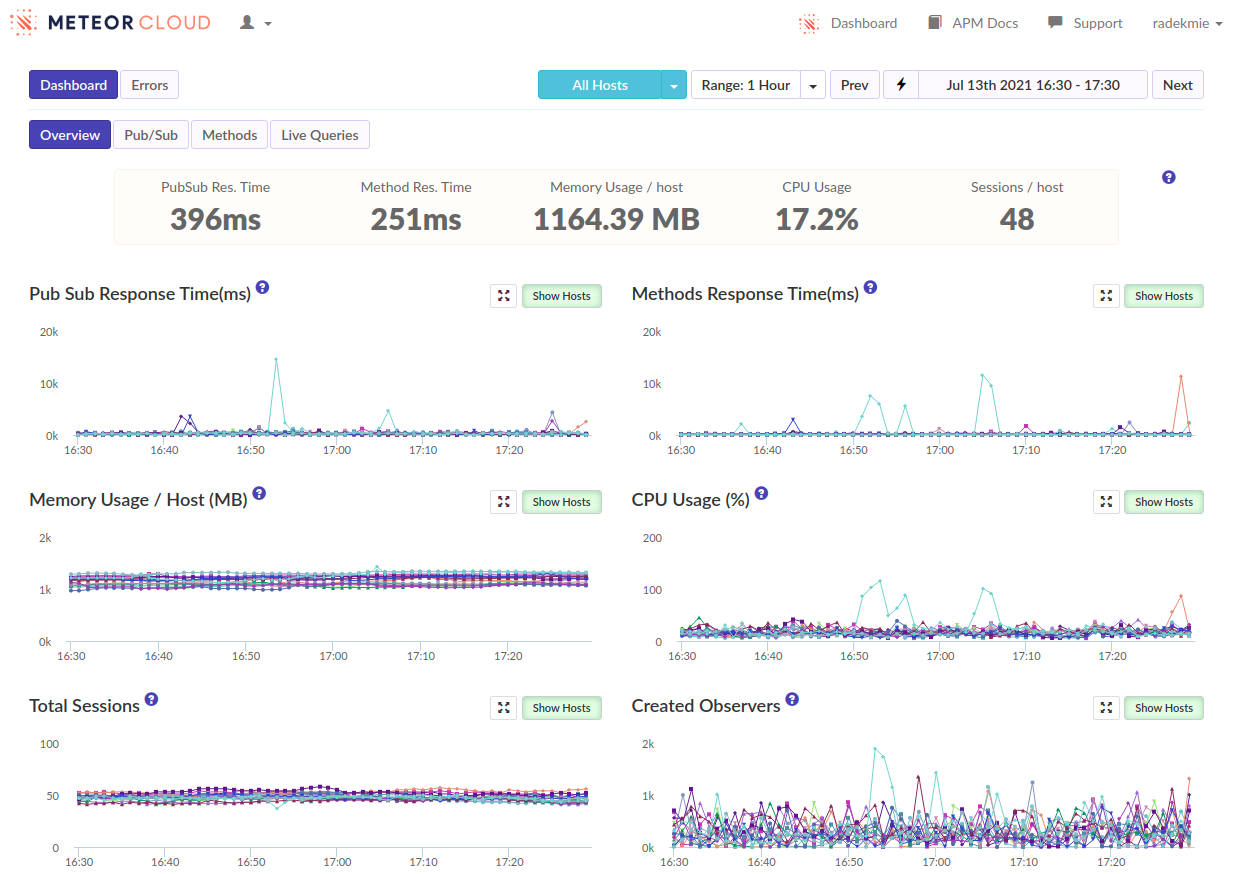
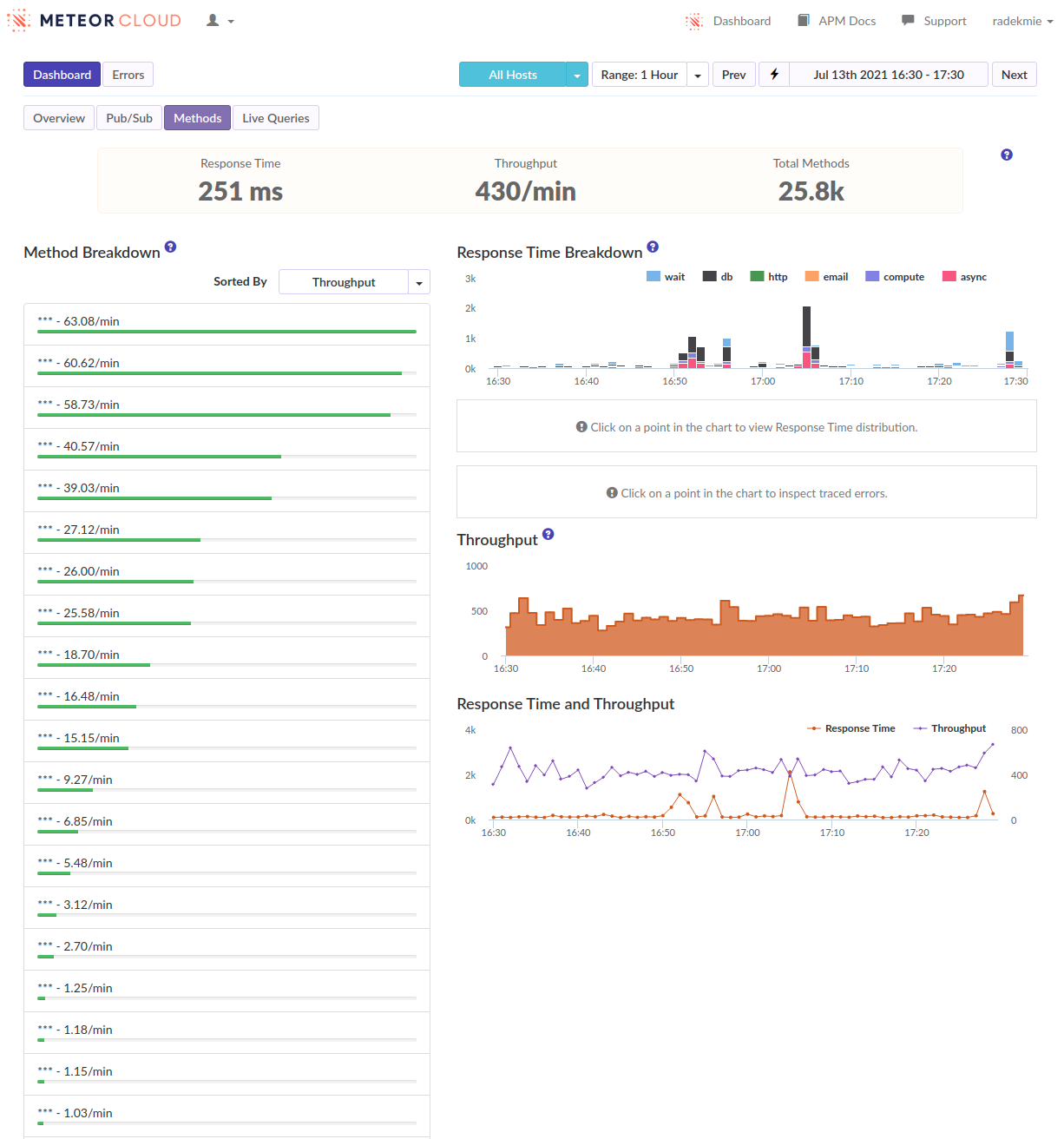
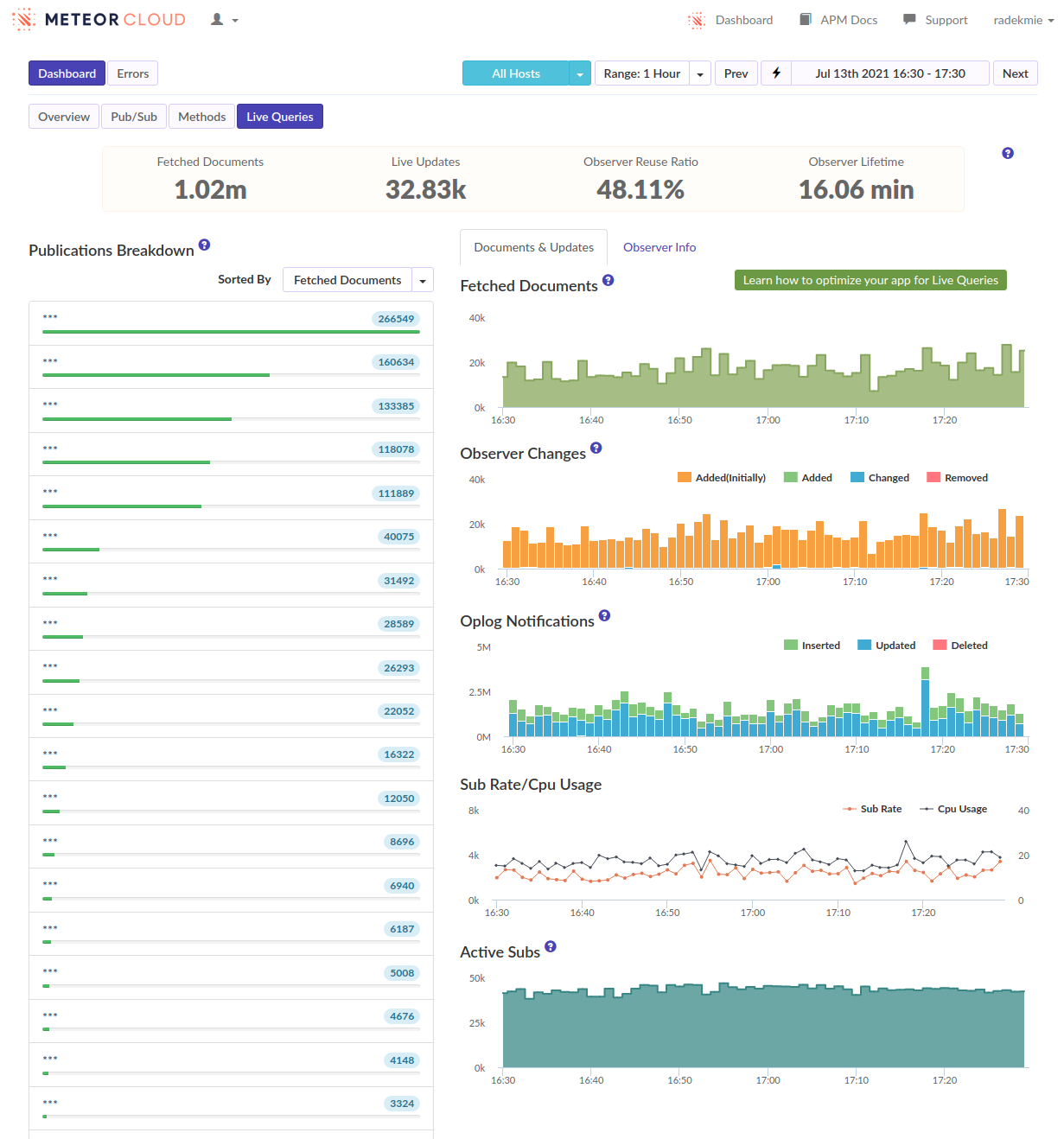
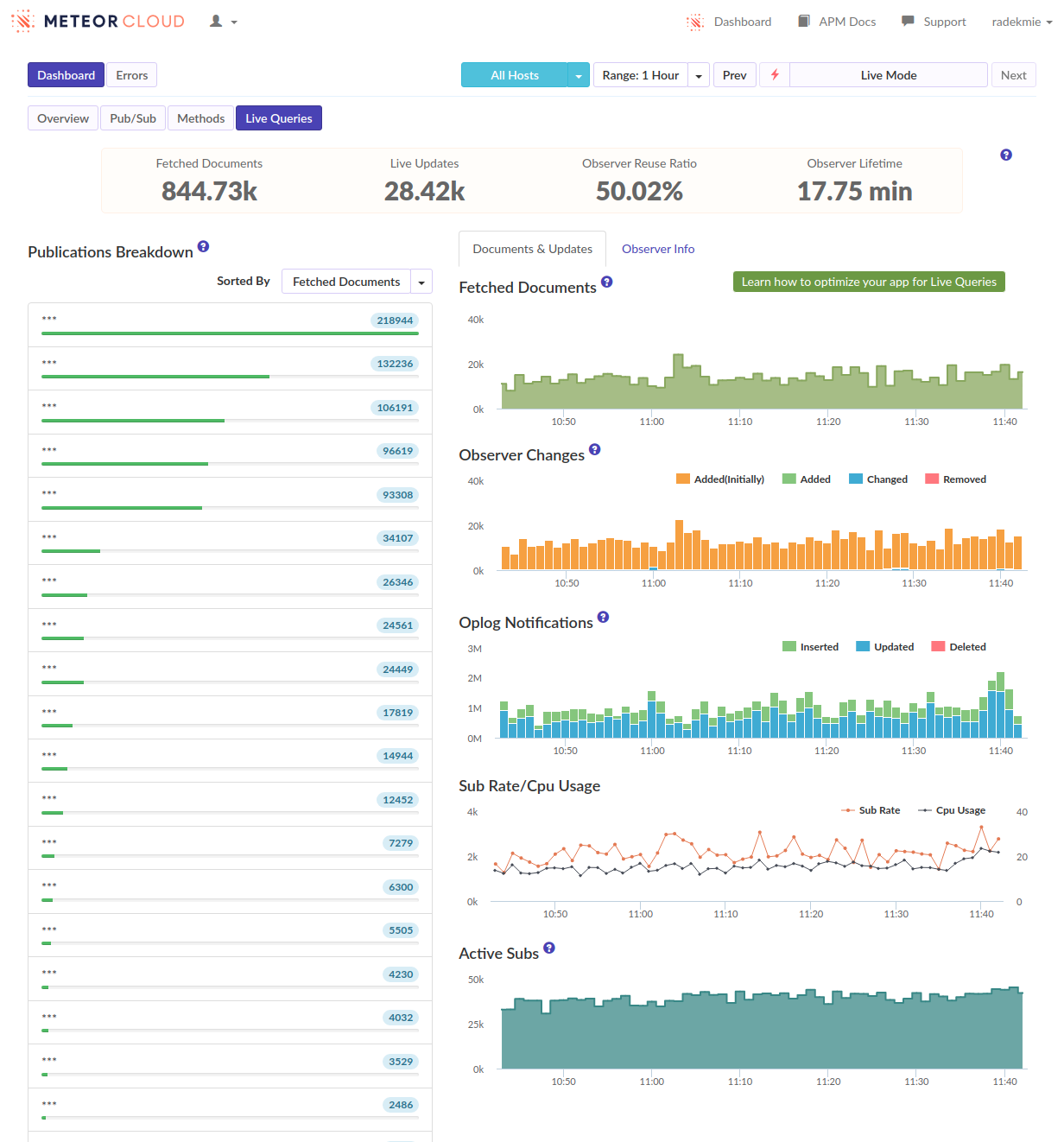
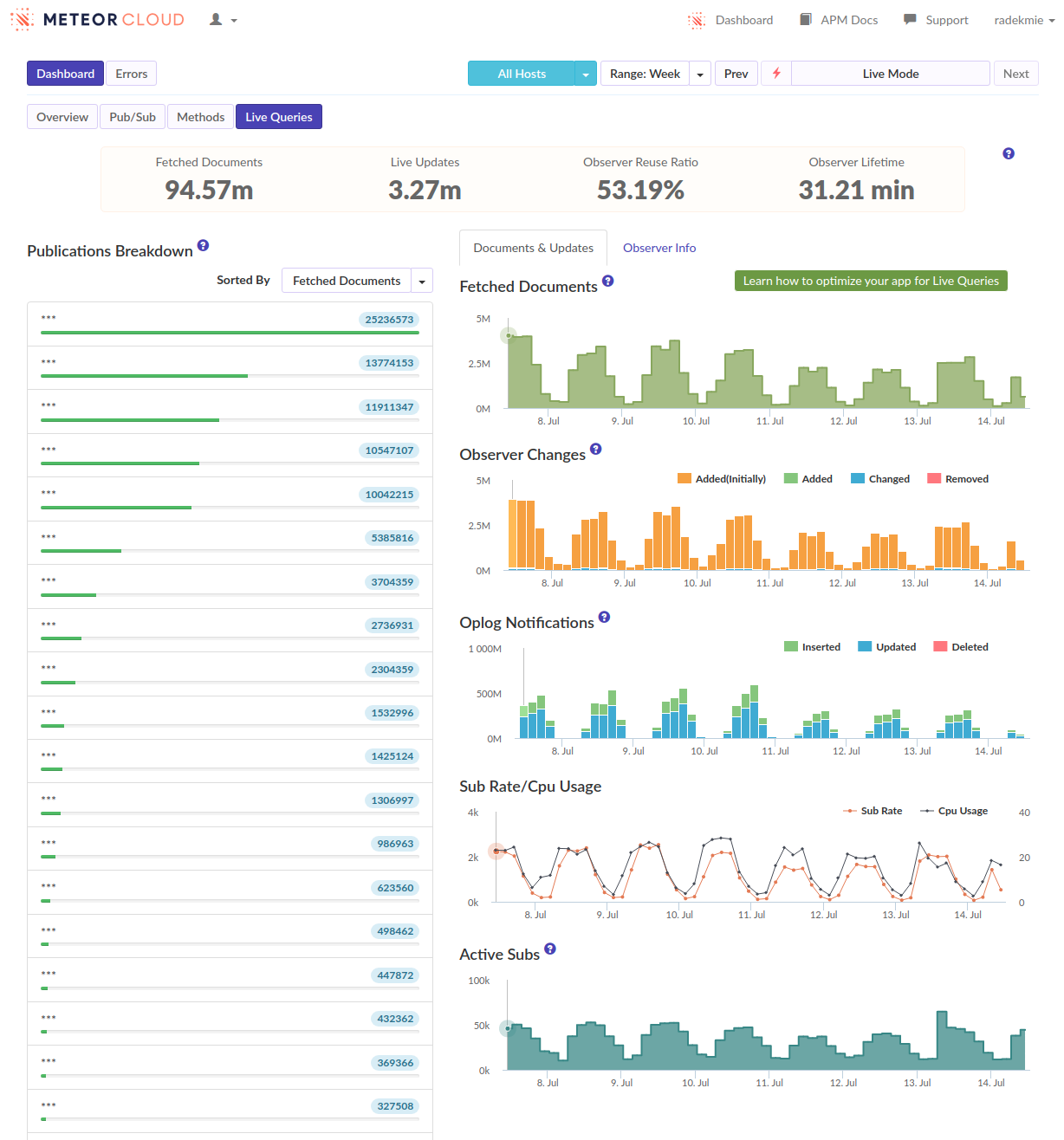
I’ve often seen ‘login’ as the biggest spike when viewing our methods in Monti but never investigated too much. […]
So in the first stage you load only the absolutely necessary stuff like permissions/roles which loads a ‘logging in’ page and once those subscriptions have completed it moves you to the main view which then triggers the rest of the subs ?
- We can see that as well, in many of our apps. But I think it’s not really true - it’s just how the APM works and it kind of “merges” the following subscriptions and method calls into the login. Or at least it looks like it in our case.
- That’s something we went with and it really helped. I’ll write a little bit more at the end of my post.
@a4xrbj1
Do you have a lot more than 300k lines of code? […]
I was curious myself. And we are almost there: 335k lines in total, 295k without blank lines and comments.
@peterfkruger
You could build a test version of your app that requires no login at all. […]
Login with username+password leverages bcrypt, which is by design heavy on the CPU. […]
- It won’t work as it’d either require rewriting a big chunk of the app or calling the login method automatically, that doesn’t really make sense, as that’s exactly what Meteor does with login tokens.
- I’ve been working with Meteor for almost 6 years now and I’ve never seen Bcrypt taking significant amount of CPU, even in lightweight apps with thousands of users logging in at once. But maybe it’s just me.
@efrancis
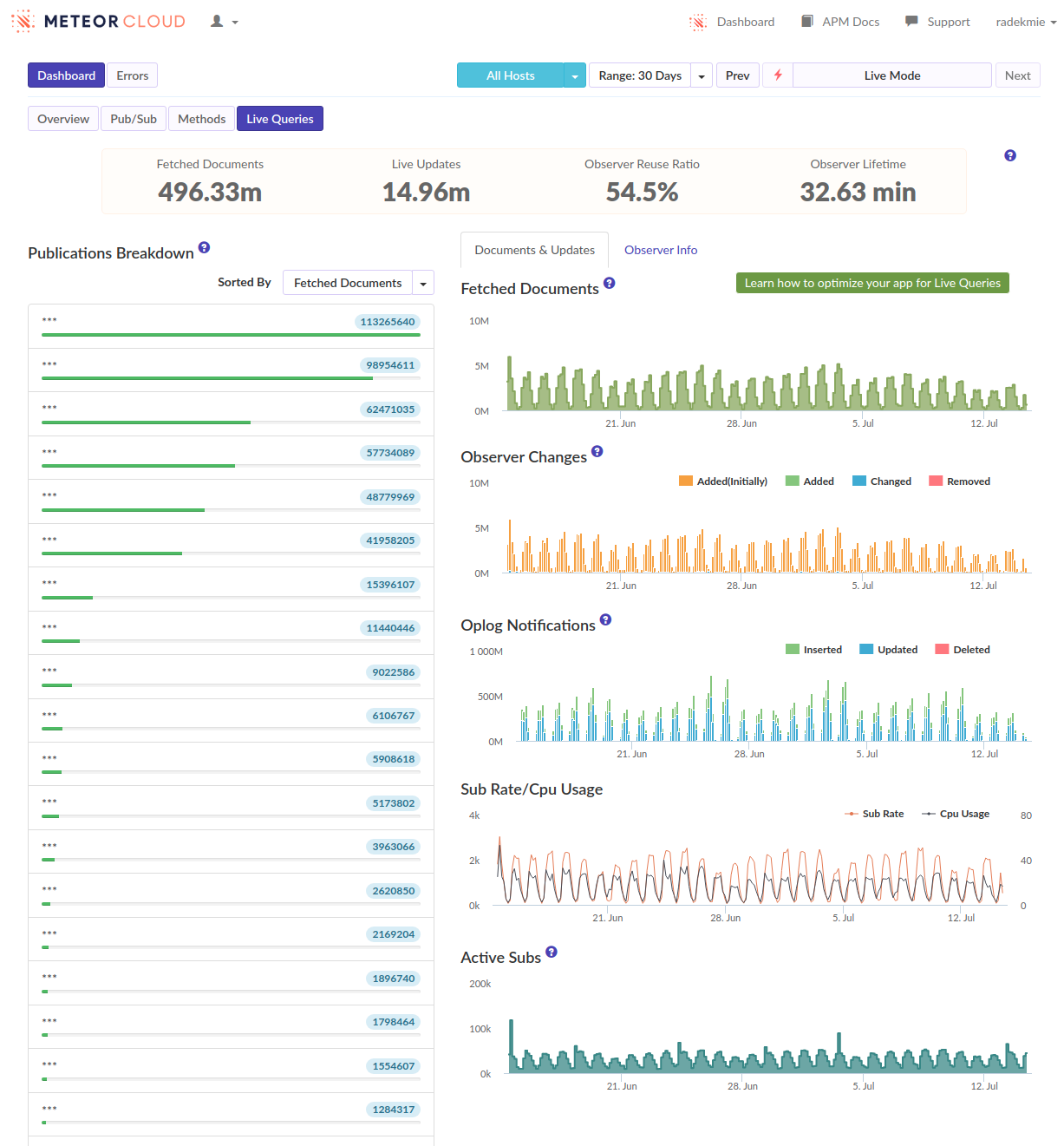
From this discussion and those APM screenshots it sounds like you need to reduce the amount of documents being subscribed to, and ideally the overall number of subscriptions. This really seems like a data model and/or over-subscribing problem that there isn’t some magical fix for.
We know that, but as I said, we’d rather look for anything that could help us in the meantime. And no, we weren’t looking for a “magical fix”, but rather a temporary workaround. In the end, loading times are not a problem – unresponsive servers are.
@wildhart
Do you store any custom data on the user objects? […]
No, not much. Only the “usual Meteor stuff” and some information about the tenancy.
@ramez
@radekmie our version of redis-oplog was specifically designed to handle large loads. […]
As I said, we’re already planning to use such a package and yes, we’ll try yours as well. Thanks for sharing!
I think we’re fine, at least for the time being. What helped was some kind of scheduling and throttling of the publications. To be exact, we have quite a few places where we do a couple of Meteor.subscribe calls at once (up to 15!). Before we’ve waited for all of them to be .ready(). Now, we do not call the next subscribe as long as all the previous subscriptions are not ready. It made loading times longer, but spreading it like that made our servers responsive at all times.
Thank you all for your time! I hope the entire community will benefit from the ideas (and packages) shared in this thread!