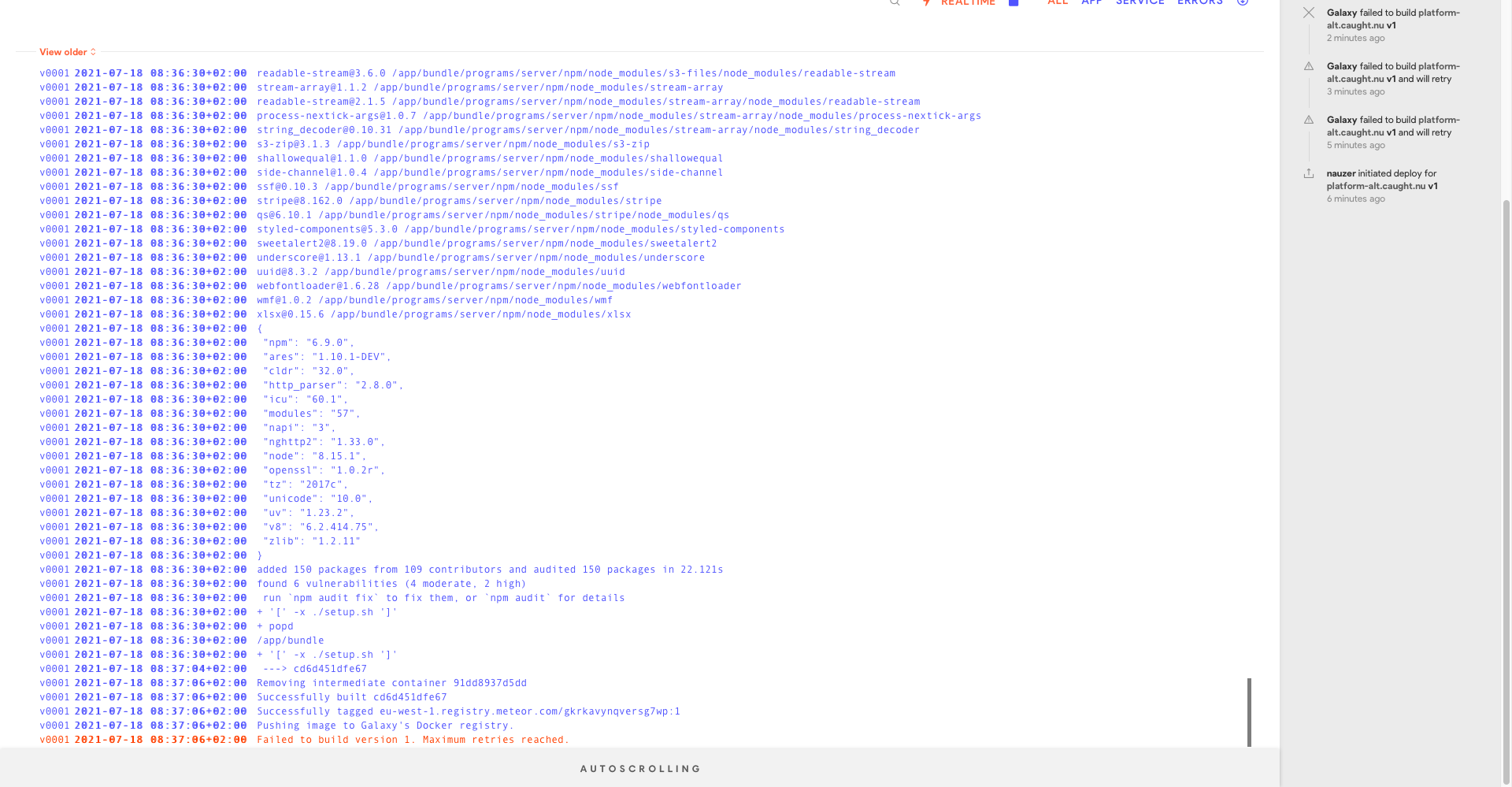
Our Galaxy applications have crashed with the following log entries on Galaxy.
2021-07-18 04:31:14+02:00The container is being stopped because Galaxy is replacing the machine it’s running on.fjahz
2021-07-18 04:31:16+02:00Application exited with signal: terminatedapp
2021-07-18 04:31:25+02:00The app is unavailable, this is not a Galaxy issue, you should analyze your app, read more here Container environment | Galaxy Docs
Trying to deploy new is reject with the following errors:
Talking to Galaxy servers at https://eu-west-1.galaxy-deploy.meteor.com
Error deploying application: 502 Bad Gateway: Registered endpoints failed to handle the request. If you’re the owner of this app, see this article for more information: Error Types | Galaxy Docs (2)
Furthermore accessing Galaxy seems to be super unstable as well. Page loads take forever. With page load errors as well:
502 Bad Gateway: Registered endpoints failed to handle the request. If you’re the owner of this app, see this article for more information: Error Types | Galaxy Docs (2)
Stop/Start, Scale up/down, New deploy are ALL not working without any log entries.
Trying to redeploy a new application now to see if we can redirect DNS.
Deploying NEW application does not work. It builds alright locally, uploads to galaxy. Galaxy successfully builds the Docker image and writes it to registry. However afterwards it cannot build it to spin up a container. No further visible logs:
It looks like Galaxy is having problems spinning up container from any (NEW or EXISTING) Docker container image. See errors above.
Since ALL affected applications in our organization that are now down have the following log entry:
dvyfm2021-07-15 03:15:37+02:00The container is being stopped because Galaxy is replacing the machine it’s running on.
It seems like Galaxy initiates a container replacement which is not working because the new container cannot be spun up. Leaving the application in UNAVAILABLE state.
I think this is quite an urgent matter and I hope someone will look at this soon!
@rijk ofcourse it can always be worse but this one it quite a severe one if you ask me … Just wondering why they would close a container before a new one has finished spinning up in this scenario.
Migrated all to custom (mup) servers now and waiting for DNS records to flush.
Guess we need to work on a more solid swap to another hosting platform for the future but curious what the folks at Meteor/Galaxy are going to say on this one…
https://status.meteor.com lists “All Systems Operational”. So their status reporting clearly doesn’t cover everything. Because this suddenly stopped working, I changed nothing, my last deploy was a month ago.
We have applications (running exactly the same bundle/codebase) that are up and running.
The issues seem to start when a new container needs to be spun up for any reason, e.g.
either resize a container, deploy a totally new application or if Galaxy decides to kill your container (The container is being stopped because Galaxy is replacing the machine it’s running on…)
So advice:
Don’t scale
Don’t stop/start
Better hope your code is solid because unhealthy container replacement likely also fails if any error causes the container to crash.
Don’t deploy to existing applications (Haven’t tested deploying to an application that is still running but my fear is it will have the same result and I’m not willing to give it a test for obvious reasons)
Have a backup ready in form of a mup deployment or move to ap-southeast-2 region (unvalidated - based on report above by @kevanstuart ) which would require you to delete the existing application if you need to use the primary domain. Means you loose any logging or version history.
By the way, for me it started at almost the exact same time.
2021-07-18 04:31:12+02:00 The container is being stopped because Galaxy is replacing the machine it's running on.
2021-07-18 04:31:14+02:00 Application exited with signal: terminated app
2021-07-18 04:31:25+02:00 The app is unavailable, this is not a Galaxy issue, you should analyze your app, read more here https://galaxy-guide.meteor.com/container-environment.html#unhealthy
Ok, app is finally back online after almost 15 hours.
“We have a self-signed certificate in our Docker Registry that needs to be renewed each 5 years and it expired yesterday night.”
Wow… Will be interested to hear what steps you will take to prevent this type of things from happening in the future. This all feels really unprofessional, and I’m especially concerned by the fact that this was not picked up until after 13 hours (with the status page showing “All Systems Operational”). This does not give me faith in Galaxy.
Hi @rijk we understand your frustration and we are frustrated as well.
We have more than 400 monitors in Datadog that calls us immediately and we always have engineers on call to act on eventual issues.
The problem here was that these certificates from the Registry were not included in the monitoring and that is why they started to fail without notifying us.
Also, most of the apps were not affect and because of that the errors in tasks creation (ECS containers) and image builder fails (new deploys) were not enough to trigger other monitors that we have. It’s normal for tasks and images to fail sometimes but we are going to reduce these limits as well do it will be more sensitive next time.
We work really hard to make our services reliable for all the apps and we are very proud of the results that we have achieved so far but unfortunately in some rare cases problems happen. There is no justification, we just need to be better, improve our monitors and think about more things that can go wrong.
Just to be clear as well about support, we also have support levels where our customer can trigger a PagerDuty immediately, this is available for enterprise clients for example but as usually enterprise clients run their apps with more than 3 containers (high availability) so in this case they were not affected.